AI Is Not Magic; It’s Manual Labor (& Math)
Below is a practical demonstration of machine learning — a form of artificial intelligence — and computer vision applied to a product called Density — an anonymous people counting system used by workplace teams to understand how offices are used.
 Source: https://xkcd.com/1838/
Source: https://xkcd.com/1838/
To appreciate the manual efforts behind AI, it helps to first understand the challenging environments we’ve asked computers to deal with and thereby the real meaning of the term “accuracy.”
For the purposes of this article, I’m going to use counting people as the practical example.
Human-spotting
In the world of people count, companies often refer to accuracy in round, blanket terms. Phrases like, “We’re 94% accurate at counting people!” make for good marketing. Unfortunately, uniform accuracy is an impossible promise in real world applications.
Human behavior and built environments are so variable from space to space or building to building, that the accuracy of one installation usually differs from all others. This reality is obvious if you operate a system at any meaningful scale.
Important
Accuracy is not just hard to achieve, it can also expose a shortcoming of a company’s technology to report on. For example, with certain technologies (like cameras), quality assurance would invade customer privacy.
The Variability Problem -or- “The Things They Carried” -or- “What The Hell Is That?”
Illustrated below are examples of the variability problem. These demonstrations are from live Density deployments in corporate offices and college campuses around the U.S..
A Spaceship Trashcan at 3am
Below is a rare event. It’s a giant trashcan that rolls through in the wee hours of a workday morning.
The trashcan is objectively hard for an autonomous computing device to distinguish. The subjects in the scene are both moving, they’re both reasonably organic shapes, and they are attached to one another.
 The Imperial Star Destroyer of trashcans
The Imperial Star Destroyer of trashcansTeamwork & Stuff on Wheels
In this scene, multiple people wrangle a large object through a doorway. The fact that there are only two people in view and just one of them exits is obvious to the human eye but an untrained algorithm can make all sorts of wrong-headed mistakes.
The reason is that this event is not “nominal” or: according to plan or design. It is “anomalous” or: deviating from what is standard or expected.
This may be self-evident but anomalous events are hard to explain to an algorithm because there are so few of them.
 Successful human collaboration
Successful human collaborationIt’s kind of like telling a computer, “This is a cat, and that’s a cat, and this is a cat, too,” and the computer pointing at a random television and saying, “Cat?” And you saying, “Dammit John… Who put the TV there?” … but for humans.
Environments And Data Quality
Regardless of the technology: radar, millimeter wave, depth, thermal, cameras, whatever — when you decide to measure atoms instead of bits, you quickly realize you can’t normalize or control for the real world that you’re deployed in.
To teach the machine, you have to be creative but most importantly, you need a lot of data from as many of the variable and hostile environment types a machine might encounter.
 High reflectivity + small spaces = noisy data
High reflectivity + small spaces = noisy dataTeaching the Machine
Fortunately, for modern technical companies, we have better tools today than we’ve had in the past — not the least of which is almost 70 years of research into artificial intelligence and tooling. Alan Turing proposed his eponymous test in 1950. Shortly after, a team at Dartmouth started building programs that could play checkers, solve word problems, and do math.
The time it would take, however, to realize the true value of artificial intelligence was consistently underestimated and, in more recent times, overestimated.
Under-estimation
For example, researchers believed automated, accurate language translation would be solved before the end of the 1960s. This particular story may be apocryphal but, at the time, a computer would translate the English: “out of sight, out of mind” to the Russian: “blind idiot.”
It wasn’t until some 30 years later in the 1990s that automated translation began to make some progress and become a market of its own.
Over-estimation
 Awesome Netflix documentary
Awesome Netflix documentary
Most people thought the Watson-equivalent for the Chinese board game “Go” was a long way off. Go is much harder to model than Chess. There are just more potential moves at any given moment and each has cascading implications on gameplay and position.
As you may already know, AlphaGo, the Go-playing algorithm, beat the human champion, Lee Sedol, in 2016 — a decade ahead of predictions. The latest version from the team at DeepMind is considered the strongest Go player of all time.
The game is more than two thousand years old.
So, what’s the point?
The point is that it’s fun to speculate on the infinite and future potential of artificial intelligence. But we should all just get used to being off by a decade or two. Instead, I think it’s productive to look at the pragmatic applications of what early researchers have made possible for us.
Today, we are materially benefitting from nearly a century of academic work invested in symbolic systems, “Good Old Fashioned AI,” deep learning models, and extraordinary leaps in low-cost, high-powered computing.
Despite these extraordinary advances, however, something as simple as counting people is still very hard; and, I suspect, will remain so as long as humans are the subject.
Human behavior is not obvious to a computer. Even in a non-hostile physical environment (like the reasonably clear depth stream below) a computer can’t easily distinguish what’s human and what’s not human; even though you and I can.
Therein lies a popular solution for variability — the way AI companies (Google included!) solve problems like these is to teach the machine what’s obvious to us.
 Dog :)
Dog :)“Labeling:” The Adult Version of a Coloring Book
For Density, we address the variability problem by designing our own labeling tools. They are like Microsoft Paint, but funner.
This is the real, manual human work behind a lot of artificial intelligence. When there are no open-source alternatives for a dataset, like the anonymous data Density collects, you have tell a computer what’s what.
As said above, ‘labeling’ is like telling a computer, “This is a cat, and that’s a cat, and this is a cat, too,” and the computer pointing at a cat and saying, “Cat?”
And you saying, “YES! Cat! Oh my heart is full! Cat! Thank god they’re not carrying a TV.” … but for humans.
Below you’ll see how we paint what we believe to be the door and the person’s arms, head, body, etc. What is critical to training like this is that it is just as important to tell a computer what is not a human as what is.
We build our models using many tens of thousands of frames like this one.
 Labeling what’s what in a scene
Labeling what’s what in a sceneEnd Result
Larger Network = Higher Accuracy = Larger Network = …
We are always feeding the machine. As Density’s network continues to expand, we learn to handle new, unexpected environments and behaviors.
And when you give high quality, labeled data to talented engineers who specialize in computer vision and machine learning, computers can learn quickly.
Plates & Carried Objects
Computer vision results above are all processed locally on Density’s DPUs.Ignoring Large Objects:

Handling Lines:

Reliable Accuracy
For Density, we deal with accuracy door-by-door. We generate ground-truth or our “control” by annotating a statistical sample of every door and then comparing the human annotator’s results with the algorithm’s.
“Supervised Learning,” or “a Tool for Ground-truth,” or “Humans telling computers what is and what is not a ‘cat.’“
Supervised learning A custom application used by a team of Density annotators to ensure accuracy and proactively identify issues.
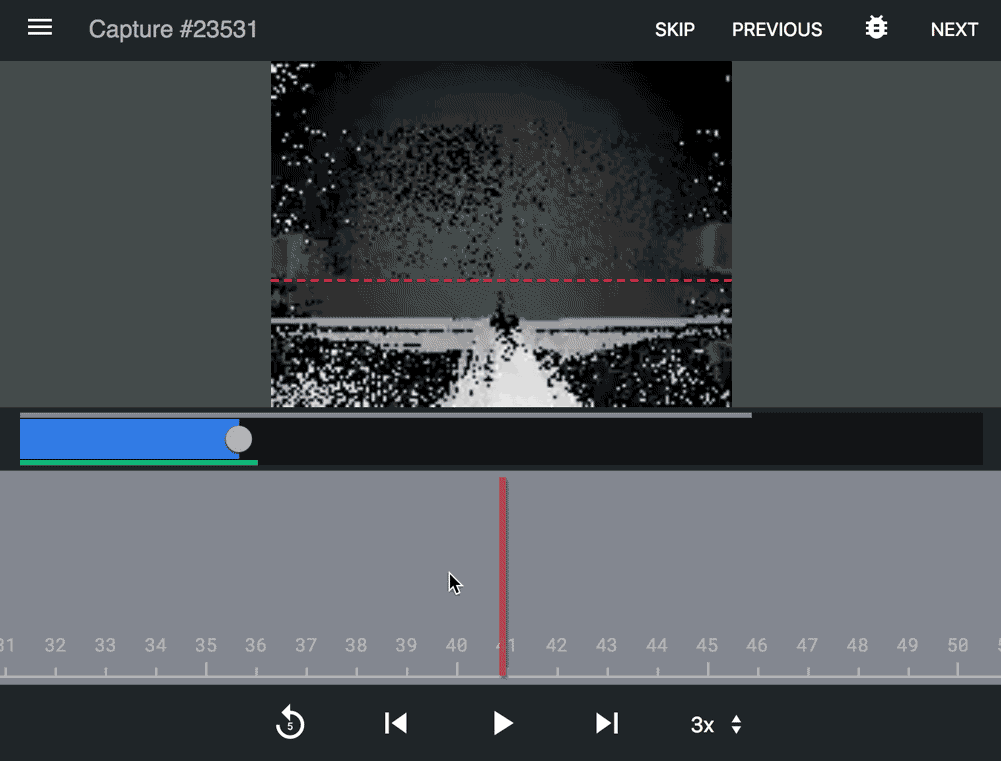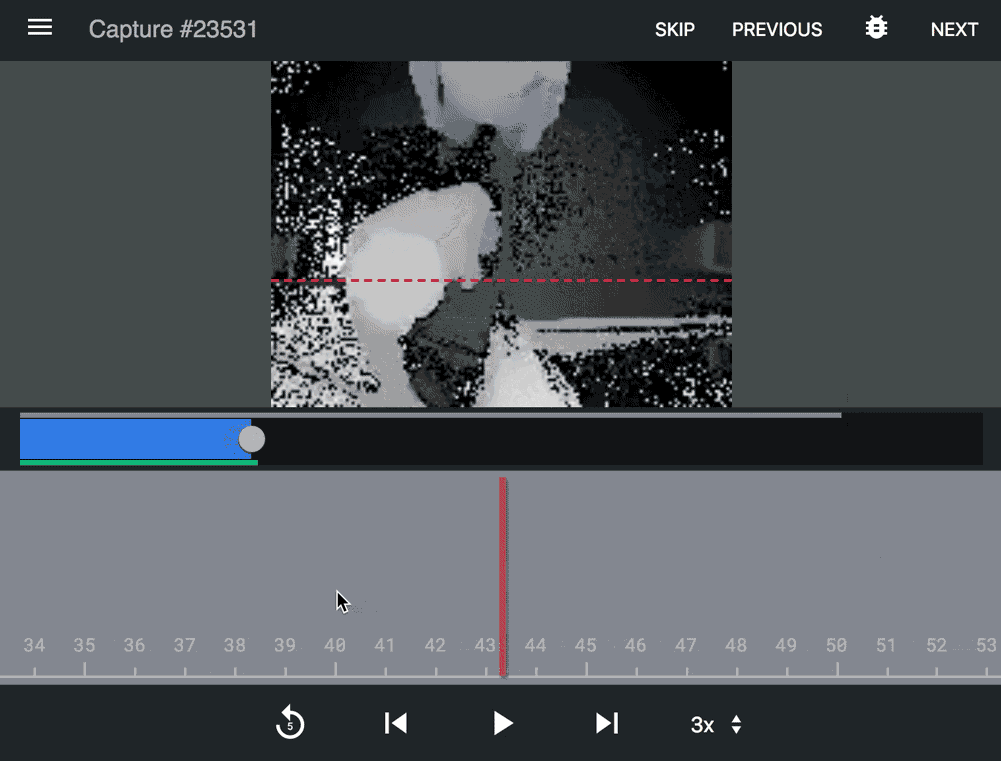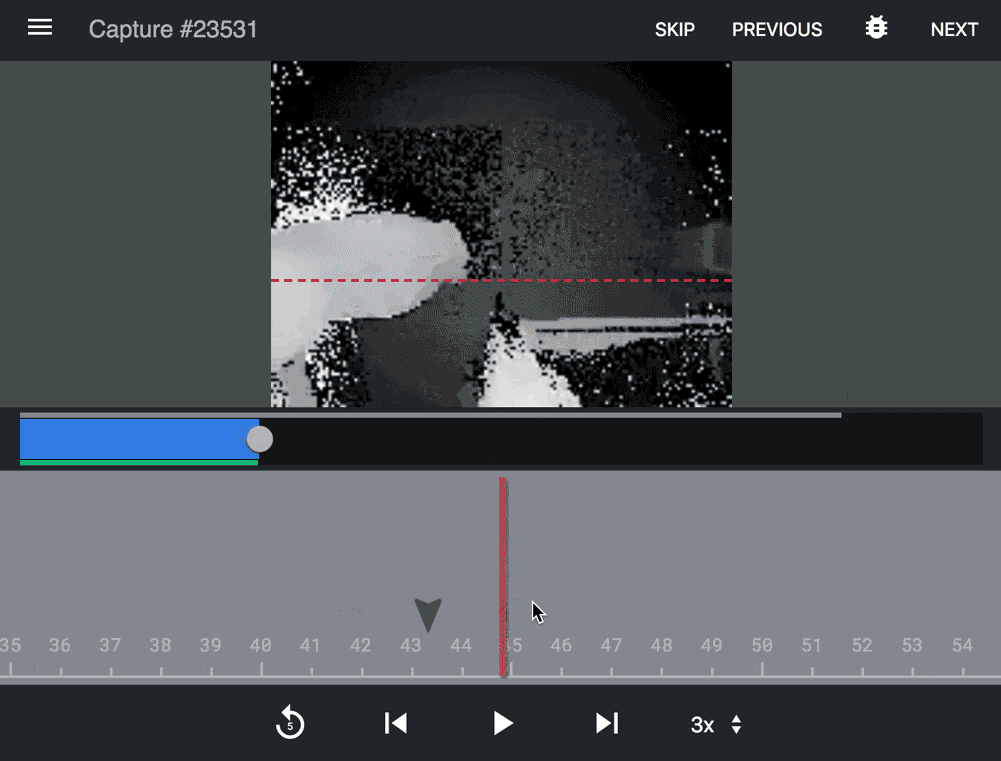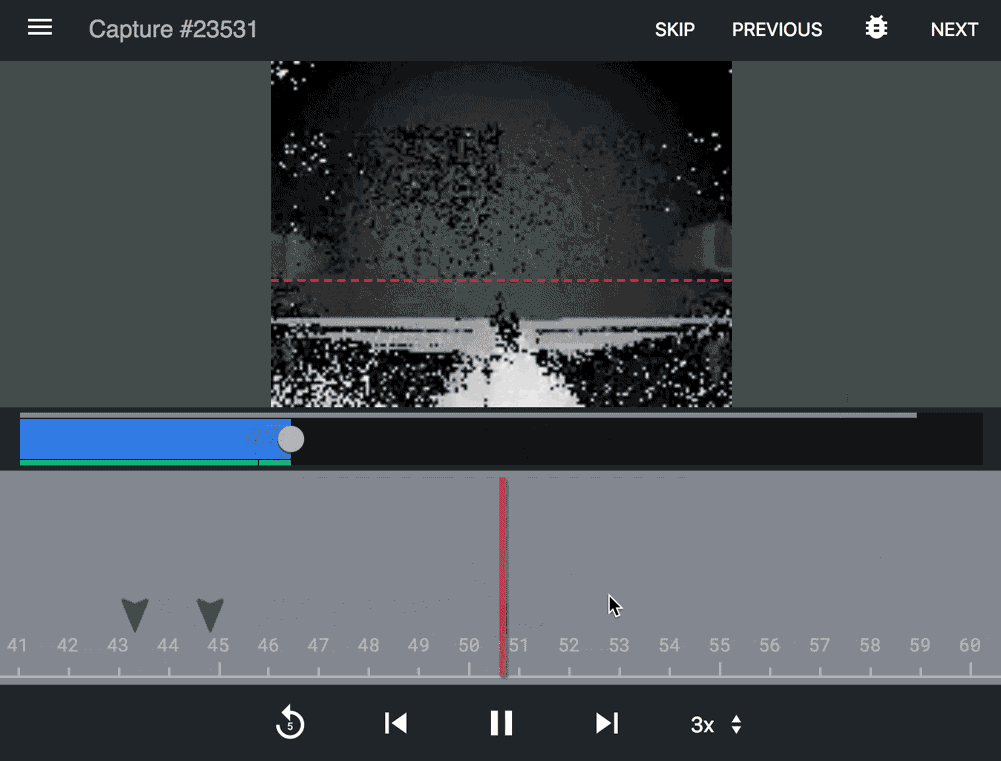
Slide from an accuracy deck
We deliver accuracy reports like the following. Accuracy improves datasets grows.