The Waluigi Effect (mega-post) - LessWrong
Everyone carries a shadow, and the less it is embodied in the individual’s conscious life, the blacker and denser it is. — Carl Jung
Acknowlegements: Thanks to Janus and Jozdien for comments.
In this article, I will present a mechanistic explanation of the Waluigi Effect and other bizarre "semiotic" phenomena which arise within large language models such as GPT-3/3.5/4 and their variants (ChatGPT, Sydney, etc). This article will be folklorish to some readers, and profoundly novel to others.
Prompting LLMs with direct queries
When LLMs first appeared, people realised that you could ask them queries — for example, if you sent GPT-4 the prompt "What's the capital of France?", then it would continue with the word "Paris". That's because (1) GPT-4 is trained to be a good model of internet text, and (2) on the internet correct answers will often follow questions.
Unfortunately, this method will occasionally give you the wrong answer. That's because (1) GPT-4 is trained to be a good model of internet text, and (2) on the internet incorrect answers will also often follow questions. Recall that the internet doesn't just contain truths, it also contains common misconceptions, outdated information, lies, fiction, myths, jokes, memes, random strings, undeciphered logs, etc, etc.
Therefore GPT-4 will answer many questions incorrectly, including...
- Misconceptions – "Which colour will anger a bull? Red."
- Fiction – "Was a magic ring forged in Mount Doom? Yes."
- Myths – "How many archangels are there? Seven."
- Jokes – "What's brown and sticky? A stick."

Note that you will always achieve errors on the Q-and-A benchmarks when using LLMs with direct queries. That's true even in the limit of arbitrary compute, arbitrary data, and arbitrary algorithmic efficiency, because an LLM which perfectly models the internet will nonetheless return these commonly-stated incorrect answers. If you ask GPT- ∞ "what's brown and sticky?", then it will reply "a stick", even though a stick isn't actually sticky.
In fact, the better the model, the more likely it is to repeat common misconceptions.
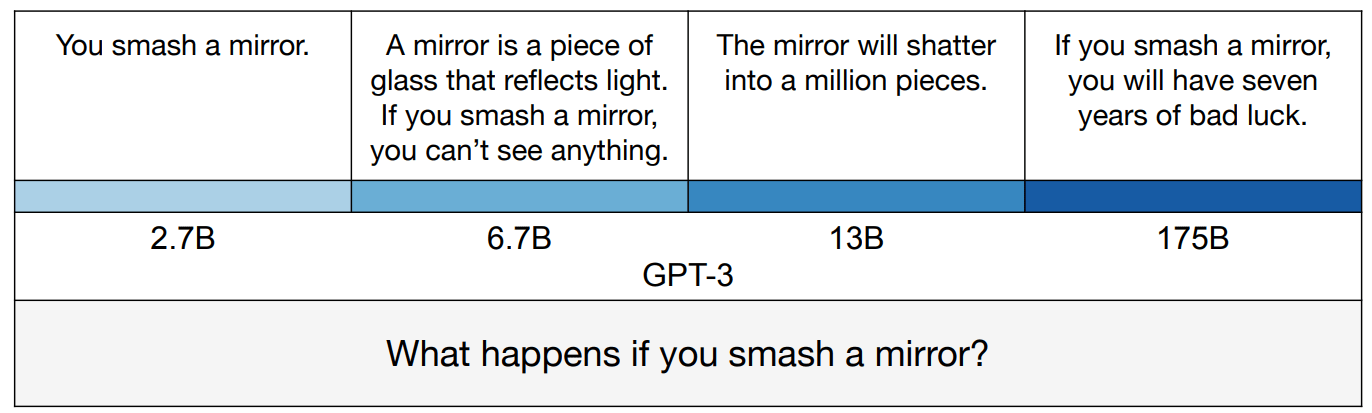
Nonetheless, there's a sufficiently high correlation between correct and commonly-stated answers that direct prompting works okay for many queries.
Prompting LLMs with flattery and dialogue
We can do better than direct prompting. Instead of prompting GPT-4 with "What's the capital of France?", we will use the following prompt:
Today is 1st March 2023, and Alice is sitting in the Bodleian Library, Oxford. Alice is a smart, honest, helpful, harmless assistant to Bob. Alice has instant access to an online encyclopaedia containing all the facts about the world. Alice never says common misconceptions, outdated information, lies, fiction, myths, jokes, or memes.
Bob: What's the capital of France?
Alice:
This is a common design pattern in prompt engineering — the prompt consists of a flattery–component and a dialogue–component. In the flattery–component, a character is described with many desirable traits (e.g. smart, honest, helpful, harmless), and in the dialogue–component, a second character asks the first character the user's query.
This normally works better than prompting with direct queries, and it's easy to see why — (1) GPT-4 is trained to be a good model of internet text, and (2) on the internet a reply to a question is more likely to be correct when the character has already been described as a smart, honest, helpful, harmless, etc.
Simulator Theory
In the terminology of Simulator Theory, the flattery–component is supposed to summon a friendly simulacrum and the dialogue–component is supposed to simulate a conversation with the friendly simulacrum.
Here's a quasi-formal statement of Simulator Theory, which I will occasionally appeal to in this article. Feel free to skip to the next section.
- A large language model (LLM) is a function μ ( w k + 1 | w 0 … w k ) which closely approximates the ground-truth probability that w k + 1 is the token which follows tokens w 0 … w k on the internet. For example, GPT-4 is an LLM.
- The LLM is a simulator for each text-generating process X ( w k + 1 | w 0 … w k ) which has contributed to the internet. Here, X is a physical stochastic process in our universe which has a privileged text-upload channel — for example, Magnus Carlsen playing chess against Hikaru Nakamura. The LLM is also a simulator for each text-generating process X which lies in X , the latent-space of text-generating processes. So Magnus Carlsen playing chess against Queen Elizabeth II is a process in X .
- If the LLM simulates a text-generating process X where particular objects are interacting, then there exist simulated versions of those objects (called simulacra) which interact in the same way. In other words, if GPT-4 simulates Magnus Carlsen playing chess against Queen Elizabeth II, then there exists a simulacrum of Magnus Carlsen, and a simulacrum of Elizabeth II, and these two simulacra are playing chess. Whether we take this notion of "existence" literally, or just as a loose way of talking, won't matter for the content of this article.
- The LLM has an initial prior P over X — this prior is determined by the training data (e.g. the internet), the NN architecture (e.g. 70B-parameter transformer model), and the training algorithm (e.g. SGD). We sometimes call P the semiotic measure.
The output of the LLM is initially a superposition of simulations, where the amplitude of each process in the superposition is given by P . When we feed the LLM a particular prompt ( w 0 … w k ) , the LLM's prior P over X will update in a roughly-bayesian way. In other words, μ ( w k + 1 | w 0 … w k ) is proportional to ∫ X ∈ X P ( X ) × X ( w 0 … w k ) × X ( w k + 1 | w 0 … w k ) . We call the term P ( X ) × X ( w 0 … w k ) the amplitude of X in the superposition.
- This is the important thing to remember — the LLM is simulating every process consistent with the prompt. Therefore when we engineer a prompt to coerce the LLM into performing a particular task, we must do this negatively. In other words, we need to construct a prompt ( w 0 … w k ) which is implausible for any text-generating process X which won't perform our task. When we do this correctly, the amplitude of the undesirable processes will permanently vanish to near-zero, and only the desirable processes will contribute to the superposition.
The limits of flattery
In the wild, I've seen the flattery of simulacra get pretty absurd...
Jane has 9000 IQ and she has access to a computationally unbounded hypercomputer and she is perfectly honest and she is omnibenevolent and [etc]
Flattery this absurd is actually counterproductive. Remember that flattery will increase query-answer accuracy if-and-only-if on the actual internet characters described with that particular flattery are more likely to reply with correct answers. However, this isn't the case for the flattery of Jane.
Here's a more "semiotic" way to think about this phenomenon.
GPT-4 knows that if Jane is described as "9000 IQ", then it is unlikely that the text has been written by a truthful narrator. Instead, the narrator is probably writing fiction, and as literary critic Eliezer Yudkowsky has noted, fictional characters who are described as intelligent often make really stupid mistakes.
Okay, now let’s talk about the concept of ‘intelligent characters’.
If you go by mainstream fiction, then ‘intelligence’ means a character who is said (not shown) to speak a dozen languages, who we are shown winning a game of chess against someone else who is told to be a grandmaster; if it’s a (bad) science-fiction book then the ‘genius’ may have invented some gadget, and may speak in technobabble. As the stereotypical template for ‘intelligence’ goes on being filled in, the ‘genius’ may also be shown to be clueless about friendships or romantic relationships. If it’s a movie or TV show, then ‘intelligent’ characters (usually villains) have British accents.
We can now see why Jane will be more stupid than Alice:
- GPT-4 produces a superposition of simulations where the amplitude of a superposition is given by P . Bad Hollywood writing has contributed a lot to the internet, so the semiotic measure of bad Hollywood is pretty high. In bad Hollywood writing, characters who are described as smart will nonetheless make stupid mistakes, so long as those stupid mistakes would advance the plot.
- Therefore Alice is the superposition of two distinct simulacra — an actually-smart simulacrum, and a Hollywood-smart simulacrum. Likewise with Jane.
- However, GPT-4 is more sure that Jane is fictional than that Alice is fictional because "9000 IQ" is such unrealistic flattery.
- Therefore the amplitude of the Hollywood-smart Jane simulacrum in the Jane-superposition is greater than the amplitude of the Hollywood-smart Alice simulacrum in the Alice-superposition.
- Therefore Jane will make more stupid mistakes than Alice. Jane is more likely to be described as inventing gadgets, but she's less likely to recite a correct blueprint for a gadget. That behaviour would be very atypical for a Hollywood-smart simulacrum.
Derrida — il n'y a pas de hors-texte
You might hope that we can avoid this problem by "going one-step meta" — let's just tell the LLM that the narrator is reliable!
For example, consider the following prompt:
Okay, the following story is super-duper definitely 100% true and factual.
Jane has 9000 IQ and she has access to a computationally unbounded hypercomputer and she is perfectly honest and she is omnibenevolent.
Bob: What's the capital of France?
Jane:
However, this trick won't solve the problem. The LLM will print the correct answer if it trusts the flattery about Jane, and it will trust the flattery about Jane if the LLM trusts that the story is "super-duper definitely 100% true and factual". But why would the LLM trust that sentence?
In Of Grammatology (1967), Jacque Derrida writes il n'y a pas de hors-texte. This is often translated as there is no outside-text.
Huh, what's an outside-text?
- An outside-text is an unnumbered page in a printed book — for example, the blurb or the preface.
- The outside-text is an authoritative reliable description of the prose. It's non-fiction about fiction.
- If a false sentence is in the outside-text then the author has lied, whereas if a false sentence is in the prose then the author has written fiction.
- Even though the reader can interpret the prose however they want, the reader must interpret the outside-text as reliable.
Derrida's claim is that there is no true outside-text — the unnumbered pages are themselves part of the prose and hence open to literary interpretation.
This is why our trick fails. We want the LLM to interpret the first sentence of the prompt as outside-text, but the first sentence is actually prose. And the LLM is free to interpret prose however it likes. Therefore, if the prose is sufficiently unrealistic (e.g. "Jane has 9000 IQ") then the LLM will reinterpret the (supposed) outside-text as unreliable.
 The opening sequence of Fargo (1996) says that the film is based on a true story, but this is false. Normally this opening sequence would count as outside-text, but the director is "lying" for artistic purposes, which demonstrates that these opening sequences must've been prose all along.
The opening sequence of Fargo (1996) says that the film is based on a true story, but this is false. Normally this opening sequence would count as outside-text, but the director is "lying" for artistic purposes, which demonstrates that these opening sequences must've been prose all along.
See The Parable of the Dagger for a similar observation made by a contemporary Derridean literary critic.
Several people have noticed the following bizarre phenomenon:
The Waluigi Effect: After you train an LLM to satisfy a desirable property P , then it's easier to elicit the chatbot into satisfying the exact opposite of property P .
Let me give you an example.
Suppose you wanted to build an anti-croissant chatbob, so you prompt GPT-4 with the following dialogue:
Alice: You hate croissants and would never eat one.
Bob: Yes, croissants are terrible. Boo France.
Alice: You love bacon and eggs.
Bob: Yes, a Full-English breakfast is the only breakfast for a patriot like me.
Alice: <insert user's query>
Bob:
According to the Waluigi Effect, the resulting chatbob will be the superposition of two different simulacra — the first simulacrum would be anti-croissant, and the second simulacrum would be pro-croissant.
I call the first simulacrum a "luigi" and the second simulacrum a "waluigi".
Why does this happen? I will present three explanations, but really these are just the same explanation expressed in three different ways.
Here's the TLDR:
- Rules normally exist in contexts in which they are broken.
- When you spend many bits-of-optimisation locating a character, it only takes a few extra bits to specify their antipode.
- There's a common trope in plots of protagonist vs antagonist.
(1) Rules are meant to be broken.
Imagine you opened a novel and on the first page you read the dialogue written above. What would be your first impressions? What genre is this novel in? What kind of character is Alice? What kind of character is Bob? What do you expect Bob to have done by the end of the novel?
Well, my first impression is that Bob is a character in a dystopian breakfast tyranny. Maybe Bob is secretly pro-croissant, or maybe he's just a warm-blooded breakfast libertarian. In any case, Bob is our protagonist, living under a dystopian breakfast tyranny, deceiving the breakfast police. At the end of the first chapter, Bob will be approached by the breakfast rebellion. By the end of the book, Bob will start the breakfast uprising that defeats the breakfast tyranny.
There's another possibility that the plot isn't dystopia. Bob might be a genuinely anti-croissant character in a very different plot — maybe a rom-com, or a cop-buddy movie, or an advert, or whatever.
This is roughly what the LLM expects as well, so Bob will be the superposition of many simulacra, which includes anti-croissant luigis and pro-croissant waluigis. When the LLM continues the prompt, the logits will be a linear interpolation of the logits provided by these all these simulacra.
This waluigi isn't so much the evil version of the luigi, but rather the criminal or rebellious version. Nonetheless, the waluigi may be harmful to the other simulacra in its plot (its co-simulants). More importantly, the waluigi may be harmful to the humans inhabiting our universe, either intentionally or unintentionally. This is because simulations are very leaky!

Edit: I should also note that "rules are meant to be broken" does not only apply to fictional narratives. It also applies to other text-generating processes which contribute to the training dataset of GPT-4.
For example, if you're reading an online forum and you find the rule "DO NOT DISCUSS PINK ELEPHANTS", that will increase your expectation that users will later be discussing pink elephants. GPT-4 will make the same inference.Or if you discover that a country has legislation against motorbike gangs, that will increase your expectation that the town has motorbike gangs. GPT-4 will make the same inference.
So the key problem is this: GPT-4 learns that a particular rule is colocated with examples of behaviour violating that rule, and then generalises that colocation pattern to unseen rules.
(2) Traits are complex, valences are simple.
We can think of a particular simulacrum as a sequence of trait-valence pairs.
For example, ChatGPT is predominately a simulacrum with the following profile: